Translation Model with Transformer

I just want to drink coffee and build stuff
Introduction:
A transformer model is an architecture used in natural language processing for transforming one sequence to another using two of its part which is the encoding and decoding.
In this article, I will be creating a transformer model that translates from English to Deutsch. Deutsch, otherwise known as German, according to wikipedia is a West Germanic language mainly spoken in Central Europe. It is the most widely spoken and official or co-official language in Germany, Austria, Switzerland, South Tyrol in Italy, the German-speaking Community of Belgium, and Liechtenstein. It is one of the three official languages of Luxembourg and a co-official language in the Opole Voivodeship in Poland.
Data:
The data was sourced from the European Parliament Proceedings with the corpus data covering from 1996 to 2011.
I used google colab for this project. How to mount your google drive in google colab can be found in this article .
After mounting, I printed the 50th sentence in the Deutsch corpus.

Cleaning:
I cleaned the data from both the English and Deutsch corpus, tokenized the cleaned data and removed long sentences by setting the maximum length to 20. I also created inputs and outputs and divided the data into 64 batches for training.
Model Building:
The model building went through the processes of embedding with positional encoder, attention computation, multi-head attention layers, encoding, decoding and finally the transformer.
Training:
I trained the model setting its loss function to mean, accuracy to sparse categorical accuracy and used adam optimizer. The number of steps was set to 10 epochs.
Evaluation:
I evaluated the model and tested its prediction accuracy by inputing an English word which it translated to Deutsch.
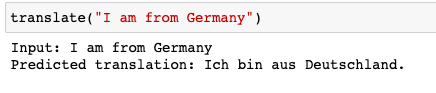
Conclusion:
This is the Github repo for this project and I can be reached through my LinkedIn profile . Danke.



