Sentiment analysis with Trax

I just want to drink coffee and build stuff
Introduction:
Trax is an end-to-end library for deep learning that focuses on clear code and speed. It is actively used and maintained in the Google Brain team.
Methodology:
I decided to use trax for sentiment analysis with twitter dataset. For more about trax, the repo is found here .
I used a conda environment with python 3.6 as python 3.8 isn't really compatible with some trax module imports.
I started by importing the required libraries and dependencies plus the tweet dataset from utils.py.
I split both the negative and positive datasets into train and validation sets, printed out the length and number of each dataset.
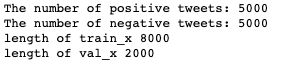
I imported the process_tweet function from the utils.py to process the dataset and built the vocabulary.
I converted the tweets to tensors and below is the result I printed

Then I tested the conversion and it passed all required tests

I created a batch generator by implementing the data generator function. From this, I generated the training, validation and testing data generator. The testing data generator does not loop and is used to test the accuracy of the model.

The output of the train generator function when tested

I implemented the required classes which includes the ReLu activation function, the dense layer and the classifier function.
Training:
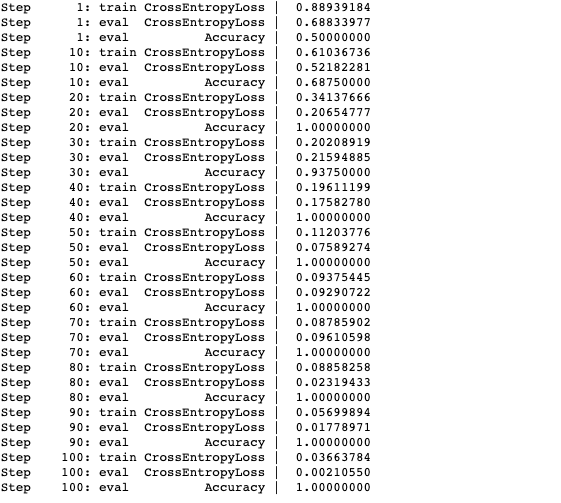
I trained the model using the training loop with 100 n_steps which outputs the train cross-entropy loss, evaluation cross-entropy loss and the evaluation accuracy.
I fed the tweet tensor to the model to make predictions.

Next step was to convert probabilities to category predictions.

Next was to implement the compute_accuracy function and test its accuracy.

Testing:
I tested the model against the validation dataset and got 0.9931 accuracy.
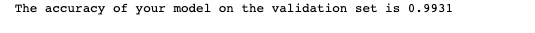
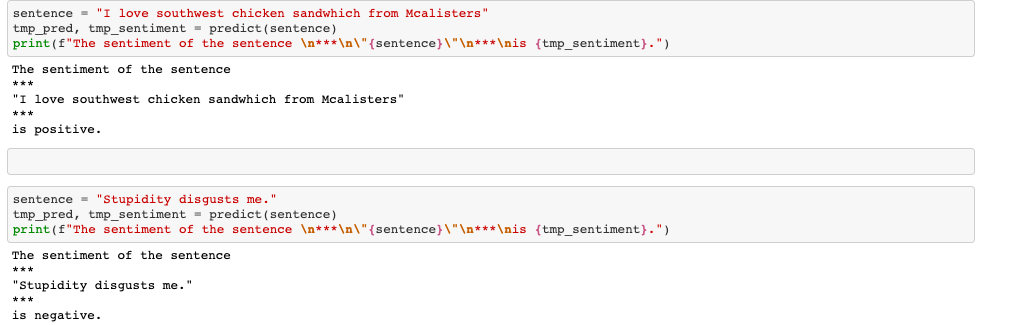
Finally, I tested with my own inputs, both positive and negative inputs to test its accuracy.
Conclusion:
There were some steps I skipped to prevent this article from being a thesis. The repo to this project is here and my LinkedIn profile for questions, suggestions or accolades. This project is from my NLP specialization certification course from Coursera.



