One Hot Encoding and Hazard Prediction


One hot encoding is a process where categorical variables are converted into a form that is fed to a machine learning algorithm for more accurate prediction.
I demonstrated the concept on a dummy data curated by me.
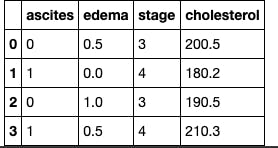
In this sample dataset, 'ascites', 'edema', and 'stage' are categorical variables while 'cholesterol' is a continuous variable, since it can be any decimal value greater than zero.
In this dataset, I applied one hot encoding to the edema column because it had three categories. One hot encoding onto this column will create feature columns for each of the possible outcome. I also applied this technique to the stage column as they are not in form of 0 and 1.
Hot encoding 'stage'
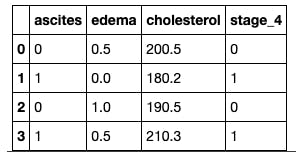
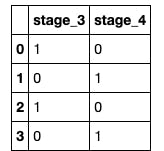 Looking at the above table, it shows that one of the features is redundant, so to avoid multicollinearity, I dropped on of the columns.
Looking at the above table, it shows that one of the features is redundant, so to avoid multicollinearity, I dropped on of the columns.
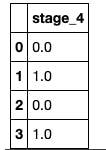
I converted the one hot encoded values to decimals since the model expects the values to be fed to it in a certain data type. I renamed the 'stage_4' column to 'stage', then converted the values to a float64 data type using numpy.
Prediction:
Using the above dataset, I predicted a new patient's hazard using the hazard function
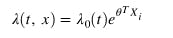
where:
Theta is the coefficient of Xi features lambda(t, x) is the patient's hazard.
I multiplied the coefficient with the features.
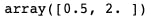
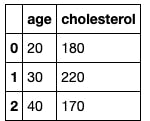
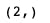
The coefficient is a 1D array, so I transposed the features which is the X
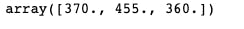
Finally, I predicted the hazards of three patients.
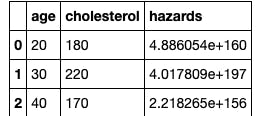
Conclusion:
I believe I have given an understanding of what one hot encoding means and how to go about it. This is the code and you can connect with me on LinkedIn . Thank you for reading.